一、CEPH 简介
不管你是想为云平台提供Ceph 对象存储或Ceph 块设备,还是想部署一个Ceph 文件系统或者把 Ceph 作为他用,所有Ceph 存储集群的部署都始于部署一个个Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。

- **
Ceph OSDs:**Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。 - **
Monitors:**Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。 - **
MDSs:**Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。
二、环境描述
- 硬件推荐:http://docs.ceph.org.cn/start/hardware-recommendations/
- 本文测试环境资源规格如下
| 主机名 | IP地址 | 角色 |
|---|---|---|
| Ceph-admin | 192.168.66.200 | Admin,ceph-deploy |
| Ceph-node1 | 192.168.66.201 | Mon,Mgr,osd |
| Ceph-node2 | 192.168.66.202 | Mon,Osd |
| Ceph-node3 | 192.168.66.203 | Mon,Osd |
| Ceph-Client | 192.168.66.204 | 客户端 |
-
**注意:**给三台Node节点单独挂载一块磁盘,大小必须大于5G;生产环境下磁盘建议1TB以上大小的容量,CPU推荐16C以上,内存24G以上,且官方建议ceph集群部署到物理机上;注意磁盘添加后不需要我们手动进行格式化分区等操作,后面通过ceph工具自动创建。
-
**
mon:**Monitors, 节点映射管理, 身份验证管理, 需要达到冗余和高可用至少需要3个节点 -
**
osd:**object storage daemon, 对象存储服务, 需要达到冗余和高可用至少需要3个节点 -
**
mgr:**Manager, 用于跟踪运行指标和集群状态, 性能. -
**
mds:**Metadata Serve, 提供cephfs的元数据存储
三、环境准备
-
第二步中我们将机器准备好,并且三台node节点上除了系统盘之外,单独挂载了一块20G大小的数据盘
-
**注意:**环境准备阶段,除了node节点需要单独挂载磁盘之外,其余节点不需要;所有ceph集群节点都需要执行以下准备阶段的所有步骤,无特殊提示的话则所有节点均需要执行相应的命令。
1、安装常用命令
- 所有集群节点安装我们会经常使用到的一些软件依赖包和命令程序
yum -y install vim lrzsz wget curl rsync git gcc make lsof pcre pcre-devel zlib zlib-devel openssl openssl-devel dos2unix sysstat iotop net-tools httpd-tools
2、更改主机名
- 所有节点按照第二步中的事先规划好的主机名进行更改,并实现集群主机名之间互相解析
hostnamectl set-hostname ceph-admin
hostnamectl set-hostname ceph-node1
hostnamectl set-hostname ceph-node2
hostnamectl set-hostname ceph-node3
hostnamectl set-hostname ceph-client
#所有节点都需要添加到hosts文件中,实现主机名解析
~]# vim /etc/hosts
192.168.66.200 ceph-admin
192.168.66.201 ceph-node1
192.168.66.202 ceph-node2
192.168.66.203 ceph-node3
192.168.66.204 ceph-client
#配置好后,我们在任意一个节点去ping其他节点的主机名,看是否解析成功
[root@ceph-client ~]# ping ceph-admin
PING ceph-admin (192.168.66.200) 56(84) bytes of data.
64 bytes from ceph-admin (192.168.66.200): icmp_seq=1 ttl=64 time=0.211 ms
64 bytes from ceph-admin (192.168.66.200): icmp_seq=2 ttl=64 time=0.854 ms
64 bytes from ceph-admin (192.168.66.200): icmp_seq=3 ttl=64 time=0.806 ms
64 bytes from ceph-admin (192.168.66.200): icmp_seq=4 ttl=64 time=0.985 ms
3、关闭防火墙
- 关闭防火墙和Selinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
getenforce
4、安装时间服务
- 在所有节点执行该操作
yum install ntp ntpdate ntp-doc
systemctl start ntpd
systemctl enable ntpd
5、创建Ceph用户
- 官网文档中已经说明,运行ceph必须使用
普通用户,并且需要保证该用户有无密码使用 sudo 的权限 - 各Ceph节点均需创建该用户
useradd cephu
echo 123456 | passwd --stdin cephu
echo "cephu ALL=(ALL) NOPASSWD:ALL" | tee /etc/sudoers.d/ceph
chmod 0440 /etc/sudoers.d/ceph
6、配置免密认证
- 实现cephu用户ssh免密登入各ceph节点,在admin节点进行操作
[root@ceph-admin ~]# su - cephu
[cephu@ceph-admin ~]$ ssh-keygen -t rsa
[cephu@ceph-admin ~]$ ssh-copy-id cephu@ceph-node1
[cephu@ceph-admin ~]$ ssh-copy-id cephu@ceph-node2
[cephu@ceph-admin ~]$ ssh-copy-id cephu@ceph-node3
[cephu@ceph-admin ~]$ ssh-copy-id cephu@ceph-client
7、添加配置文件
- 在admin节点用登入root用户,并在
~/.ssh目录下创建config文件,并将下面的配置信息添加进去
[root@ceph-admin ~]# mkdir ~/.ssh
[root@ceph-admin ~]# vim ~/.ssh/config
Host ceph-node1
Hostname ceph-node1
User cephu
Host ceph-node2
Hostname ceph-node2
User cephu
Host ceph-node3
Hostname ceph-node3
User cephu
8、添加下载源
- 在admin节点配置ceph源,并将ce文章来源(Source):浅时光博客ph源拷贝给所有node节点和客户端节点
[root@ceph-admin ~]# vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[root@ceph-admin ~]# scp /etc/yum.repos.d/ceph.repo root@192.168.66.201:/etc/yum.repos.d/
[root@ceph-admin ~]# scp /etc/yum.repos.d/ceph.repo root@192.168.66.202:/etc/yum.repos.d/
[root@ceph-admin ~]# scp /etc/yum.repos.d/ceph.repo root@192.168.66.203:/etc/yum.repos.d/
[root@ceph-admin ~]# scp /etc/yum.repos.d/ceph.repo root@192.168.66.204:/etc/yum.repos.d/
#所有节点执行创建缓存
yum clean all
yum makecache
- 在admin节点安装ceph-deploy
[root@ceph-admin ~]# yum -y install ceph-deploy
四、部署ceph集群
- 注意:如果没有特殊说明,那么接下来的操作则在admin节点上进行操作
1、创建操作目录
[root@ceph-admin ~]# su - cephu
[cephu@ceph-admin ~]$ mkdir my-cluster #之后所有的ceph-deploy操作必须在该目录下执行
2、创建ceph集群
2.1:安装distribute包
- 先下载安装python的distribute包,不然后面部署ceph集群会报错
- 下载地址:https://pypi.org/project/distribute/#modal-close
[cephu@ceph-admin ~]$ unzip distribute-0.7.3.zip
[cephu@ceph-admin ~]$ cd distribute-0.7.3
[cephu@ceph-admin distribute-0.7.3]$ sudo python setup.py install

2.2:进行创建集群
- **注意:**new后面跟的是各个节点的主机名,且可以文章来源(Source):浅时光博客实现admin节点与各node节点主机名之间互相解析
[cephu@ceph-admin ~]$ cd ~/my-cluster/
[cephu@ceph-admin my-cluster]$ ceph-deploy new ceph-node1 ceph-node2 ceph-node3
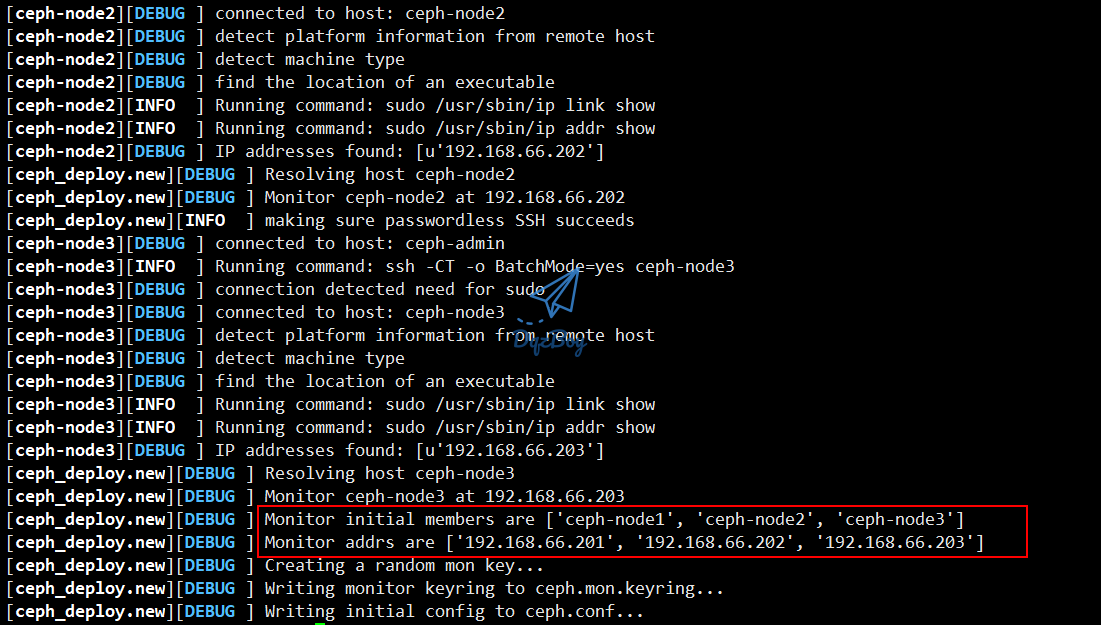
- 没有报错表示创建成功
[cephu@ceph-admin my-cluster]$ ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
- 问题:创建集群时提示缺少
pkg_resources模块的问题解决
[cephu@ceph-admin my-cluster]$ sudo pip install --upgrade setuptools
2.3:安装luminous
- 三台node节点下载epel源,注意我们已经在环境准备阶段配置了ceph源,所以这里只需要安装epel源就可以了
yum -y install epel*
- 分别在三台node节点执行以下命令进行安装软件,注意切换为ceph普通用户
su - cephu
- 通过以下命令查看当前的最新版本
$ sudo yum --showduplicates list ceph | expand
- 通过以下命令进行安装ceph
$ sudo yum install ceph ceph-radosgw
2.4:测试安装情况
- 分别在3台node节点执行下面的命令,来确认我们是否安装成功
$ ceph --version
ceph version 12.2.13 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)
3、初始化mon
- 在admin节点用cephu这个普通用户执行
[cephu@ceph-admin ~]$ cd ~/my-cluster/
[cephu@ceph-admin my-cluster]$ ceph-deploy mon create-initial
#没有ERROR报错则安装成功
- **注意:**如果之前ceph.conf配置文件中已经存在了内容,则需要添加
--overwrite-conf参数进行覆盖,命令如下:
[cephu@ceph-admin my-cluster]$ ceph-deploy --overwrite-conf mon create-initial
- 授予3个node节点使用命令免用户名权限
[cephu@ceph-admin my-cluster]$ ceph-deploy admin ceph-node1 ceph-node2 ceph-node3
#没有ERROR报错则安装成功
4、安装ceph-mgr
- 安装在node1节点上,执行安装命令在admin节点上;为安装dashboard做准备
[cephu@ceph-admin my-cluster]$ ceph-deploy mgr create ceph-node1
#没有ERROR报错则安装成功
5、添加OSD
- 分别为3台node节点添加OSD,注意磁盘名称,我这里为sdb,可通过命令lsblk或者fdisk命令查看磁盘
- 官网文档:http://docs.ceph.org.cn/rados/deployment/ceph-deploy-osd/
- **注意:**我这里只创建data盘,db和wal我这里没单独指定,如果需要单独指定则需要添加参数
--block-db /dev/sdc--block-wal /dev/sdd
#用 create 命令一次完成准备 OSD 、部署到 OSD 节点、并激活它
[cephu@ceph-admin my-cluster]$ ceph-deploy osd create ceph-node1 --data /dev/sdb
[cephu@ceph-admin my-cluster]$ ceph-deploy osd create ceph-node2 --data /dev/sdb
[cephu@ceph-admin my-cluster]$ ceph-deploy osd create ceph-node3 --data /dev/sdb
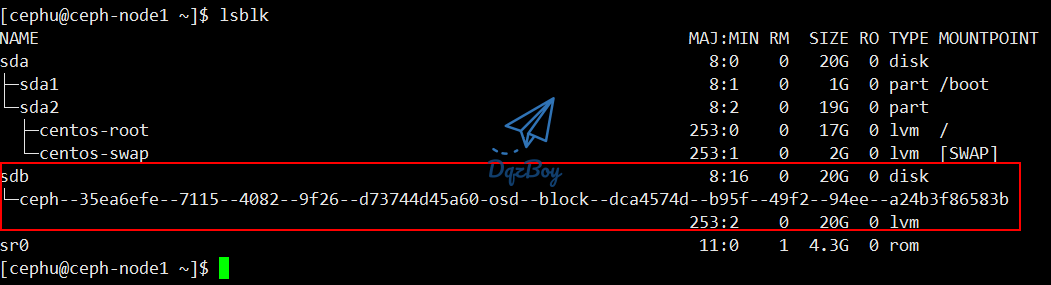
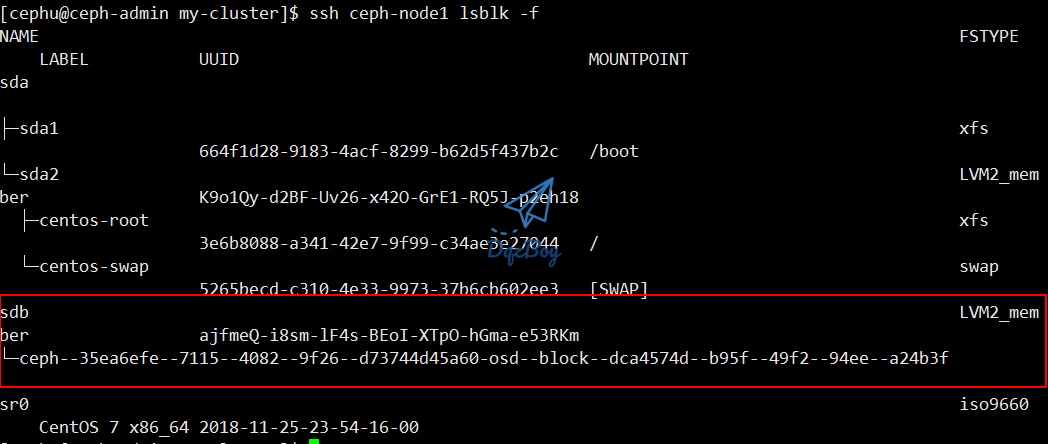
- 通过
lsblk -f命令可查看到磁盘分区情况
[cephu@ceph-admin my-cluster]$ ssh ceph-node1 lsblk -f
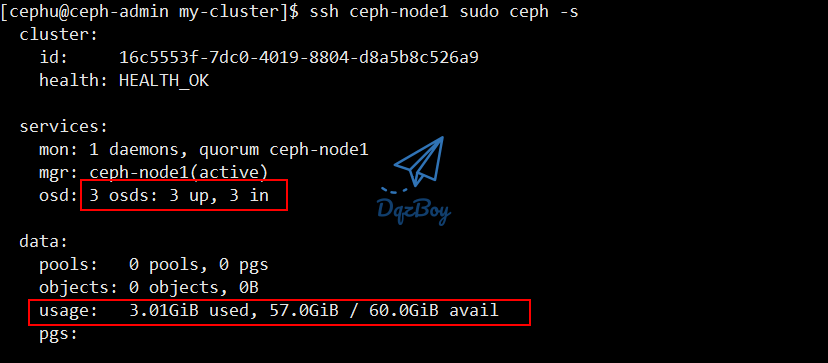
- 通过以下命令查看集群状态
[cephu@ceph-admin my-cluster]$ ssh ceph-node1 sudo ceph -s
6、部署Dashboard
- 在node1节点上部署dashboard
6.1:创建管理域秘钥
[root@ceph-node1 ~]# su - cephu
[cephu@ceph-node1 ~]$ sudo ceph auth get-or-create mgr.ceph-node1 mon 'allow profile mgr' osd 'allow *' mds 'allow *'
[mgr.ceph-node1]
key = AQDmiQhfDrBDEhAAnfwRTMv5clhbSEuetlrwyw==
6.2:开启mgr管理域
[cephu@ceph-node1 ~]$ sudo ceph-mgr -i ceph-node1
6.3:检查mgr状态
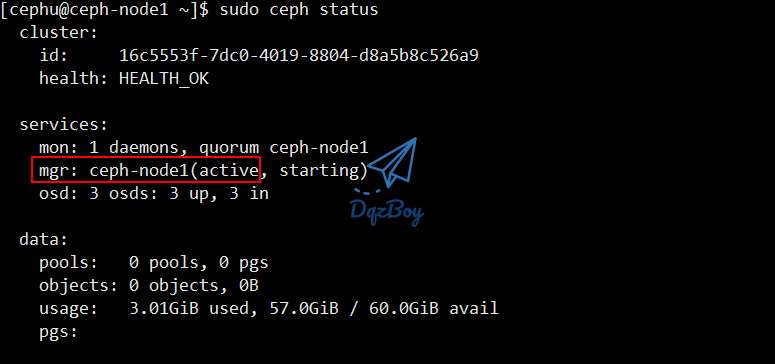
- 确保mgr的状态为
active
[cephu@ceph-node1 ~]$ sudo ceph status
6.4:打开dashboard模块
[cephu@ceph-node1 ~]$ sudo ceph mgr module enable dashboard
6.5:绑定模板mgr节点
[cephu@ceph-node1 ~]$ sudo ceph config-key set 'mgr/dashboard/ceph-node1/server_addr' '192.168.66.201'
set mgr/dashboard/ceph-node1/server_addr
[cephu@ceph-node1 ~]$ ss -tnlp|grep 7000
LISTEN 0 5 192.168.66.201:7000 *:*
6.6:浏览器访问
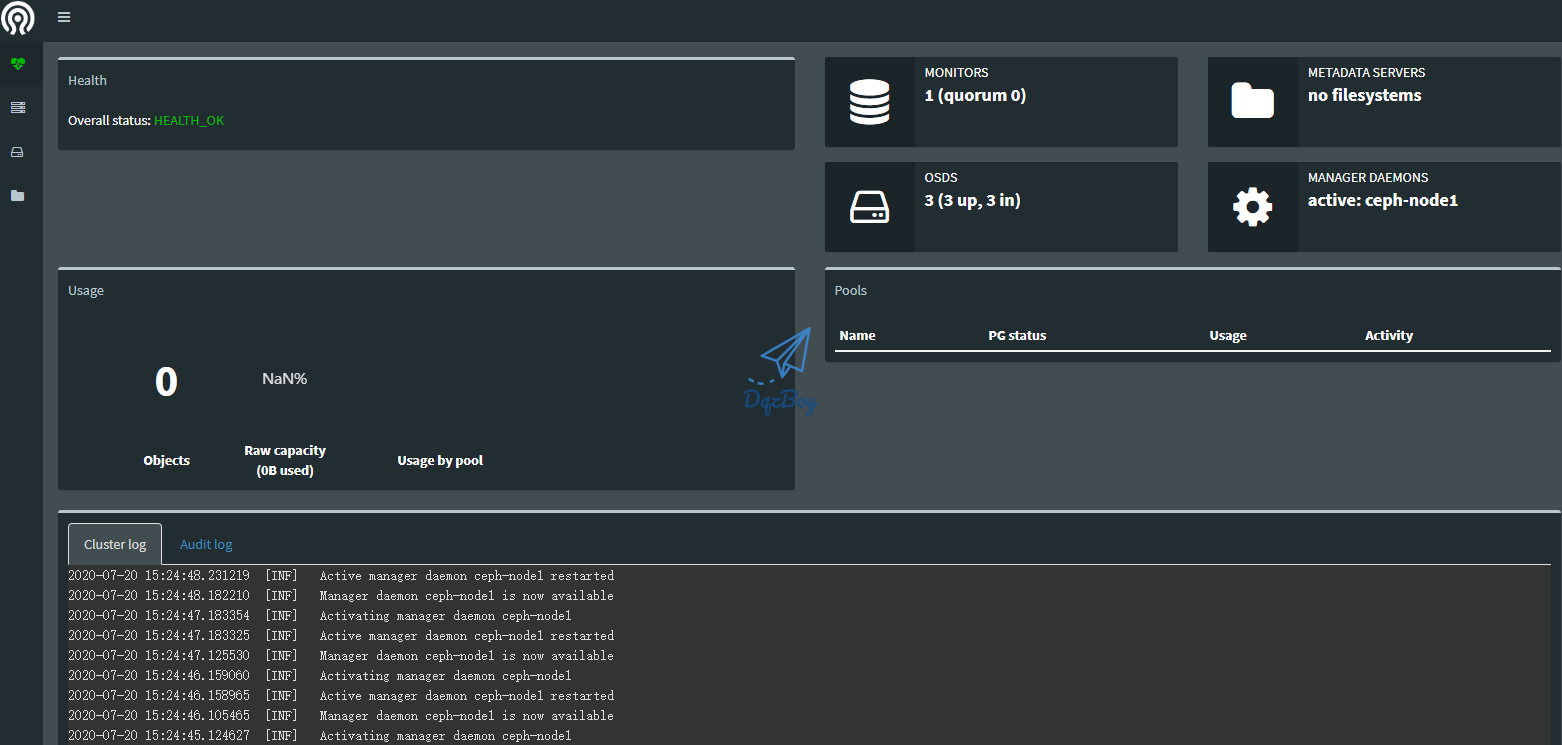
五、配置客户端
- 创建客户端使用rdb(块存储);创建块设备之前需要创建存储池;执行创建存储的命令需要在mon节点上执行,也就是node1节点
1、创建存储池
[root@ceph-node1 ~]# su – cephu
[cephu@ceph-node1 ~]$ sudo ceph osd pool create rbd 128 128
pool 'rbd' created
- 参数说明:
- 128表示如果创建的pool少于5个OSD,那么就是128个pg,5-10为512;10-50为4096
2、初始化存储池
[cephu@ceph-node1 ~]$ sudo rbd pool init rbd
3、准备客户端
- 这里的客户端就是我们规划的那台,确保客户端是可以跟admin节点实现主机名互通的
3.1:升级内核
官方推荐的客户端服务器内核版本:
- 4.1.4 or later
- 3.16.3 or later (rbd deadlock regression in 3.16.[0-2])
- NOT v3.15.* (rbd deadlock regression)
- 3.14.*
- 升级内核版本到4.x以上,接下来在客户端机器上进行操作
[root@ceph-client ~]# uname -r
3.10.0-957.el7.x86_64
- 导入key
[root@ceph-client ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
3.2:安装elrepo源
[root@ceph-client ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
- 查看可用的系统内核包
[root@ceph-client ~]# yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
3.3:安装最新内核
[root@ceph-client ~]# yum --enablerepo=elrepo-kernel install kernel-ml-devel kernel-ml -y
-
如果yum安装很慢的话,通过rpm包的方式进行安装
-
内核选择:
- kernel-lt(lt=long-term)长期有效
- kernel-ml(ml=mainline)主流版本
-
安装
[root@ceph-client ~]# rpm -ivh kernel-ml-*
3.4:修改内核启动顺序
- 查看内核默认启动顺序
[root@ceph-client ~]# awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
CentOS Linux (5.7.8-1.el7.elrepo.x86_64) 7 (Core)
CentOS Linux (3.10.0-957.el7.x86_64) 7 (Core)
CentOS Linux (0-rescue-7ba72ac2cf764cf39417d13528419374) 7 (Core)
- 修改启动顺序
[root@ceph-client ~]# grub2-set-default 0
- 重启服务器
[root@ceph-client ~]# reboot
- 再次检测系统内核版本
[root@ceph-client ~]# uname -a
Linux ceph-client 5.7.8-1.el7.elrepo.x86_64 #1 SMP Tue Jul 7 18:43:16 EDT 2020 x86_64 x86_64 x86_64 GNU/Linux
- 删除旧的内核
[root@ceph-client ~]# yum remove kernel -y
删除:
kernel.x86_64 0:3.10.0-957.el7
完毕!
4、客户端安装ceph
4.1:环境检查
- 先下载安装python的distribute包,不然部署ceph集群会报错;在client节点操作
- 下载地址:https://pypi.org/project/distribute/#modal-close
[root@ceph-client ~]# su - cephu
[cephu@ceph-client ~]$ wget https://files.pythonhosted.org/packages/5f/ad/1fde06877a8d7d5c9b60eff7de2d452f639916ae1d48f0b8f97bf97e570a/distribute-0.7.3.zip
[cephu@ceph-client ~]$ unzip distribute-0.7.3.zip
[cephu@ceph-client ~]$ cd distribute-0.7.3
[cephu@ceph-client distribute-0.7.3]$ sudo python setup.py install
[cephu@ceph-client distribute-0.7.3]$ sudo yum -y install python-setuptools
[cephu@ceph-client distribute-0.7.3]$ sudo yum -y install epel*
4.2:安装ceph
- 确保已经在环境准备阶段时客户端也配置了ceph源
[root@ceph-client ~]# su - cephu
[cephu@ceph-client ~]$ sudo yum install ceph ceph-radosgw
[cephu@ceph-client ~]$ ceph --version
ceph version 12.2.13 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)
4.3:拷贝秘钥
- 在admin【管理节点】节点上,用 ceph-deploy 把 Ceph 配置文件和 ceph.client.admin.keyring 拷贝到 ceph-client 。
[cephu@ceph-admin ~]$ cd my-cluster/
[cephu@ceph-admin my-cluster]$ ceph-deploy admin ceph-client
#ceph-deploy 工具会把密钥环复制到 /etc/ceph 目录,要确保此密钥环文件有读权限(如 sudo chmod +r /etc/ceph/ceph.client.admin.keyring )
- 修改client节点该文件的权限
[cephu@ceph-client ~]$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
4.4:修改配置
- 修改client节点下的ceph配置文件,为了解决映射镜像时出错问题。
[cephu@ceph-client ~]$ sudo vim /etc/ceph/ceph.conf
#最后添加
rbd_default_features = 1
4.5:配置块设备
- 在 ceph-client 节点上创建一个块设备 image,默认单位为M
- 语法:rbd create foo –size 4096 [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring]
[cephu@ceph-client ~]$ rbd create foo --size 4096
- 在 ceph-client 节点上,把 image 映射为块设备。
- 语法:sudo rbd map foo –name client.admin [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring]
[cephu@ceph-client ~]$ sudo rbd map foo --name client.admin
/dev/rbd0
- 在 ceph-client 节点上,创建文件系统后就可以使用块设备了。
[cephu@ceph-client ~]$ sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo
- 注意:此命令可能耗时较长。
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: 完成
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=16 blocks, Stripe width=16 blocks
262144 inodes, 1048576 blocks
0 blocks (0.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=1073741824
32 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
- 在 ceph-client 节点上挂载此文件系统。
[cephu@ceph-client ~]$ sudo mkdir /mnt/ceph-block-device #创建挂载点
[cephu@ceph-client ~]$ sudo mount /dev/rbd/rbd/foo /mnt/ceph-block-device #挂载
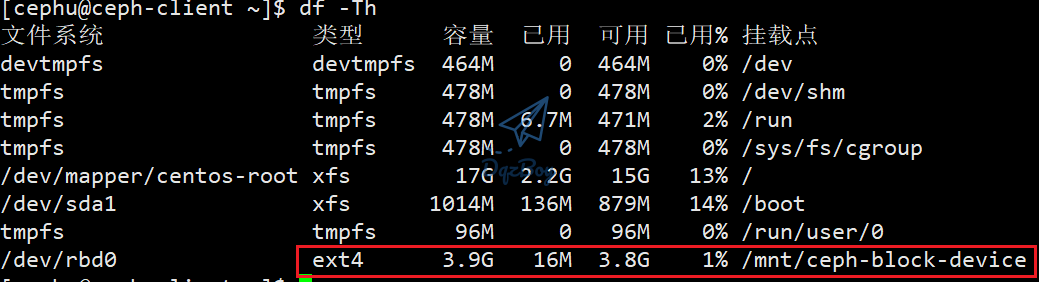
[cephu@ceph-client ~]$ cd /mnt/ceph-block-device
[cephu@ceph-client ceph-block-device]$ sudo touch dqzboy.txt
[cephu@ceph-client ceph-block-device]$ ls
dqzboy.txt lost+found